База данных, модель данных
Что такое информационные технологии? В первую очередь их можно подразделить на технологии обработки, технологии передачи и технологии хранения информации. Ниже речь пойдет о центральном понятии технологий хранения — базах данных.
Прообразы того, что сейчас называется базами данных, существовали и в докомпьютерную эпоху. Ими были библиотечные каталоги, телефонные и бухгалтерские книги и т. д. C появлением компьютеров все эти данные стали переносить в них, так появились первые компьютерные базы данных. Поначалу это были просто файлы, но со временем выяснилось, что с ростом объема данных, разнообразия и сложности задач становится необходимой специальная организация данных. Например, требуются индексы – специальные структуры, позволяющие в большой базе быстро находить нужные записи.
Базы данных в современном понимании появились в середине 60-х годов. В настоящее время их так или иначе используют практически все программные системы. Например, база данных системы управления предприятием может хранить сведения о следующих взаимосвязанных объектах:
- Сотрудники (их «паспортные данные», должности, отделы, награды, льготы)
- Организации (реквизиты, организационная структура, руководство, контактные лица)
- Финансовая информация (активы, пассивы, зарплаты, суммы по договорам)
- Оборудование: запчасти, складские запасы и т. д.
- Планы мероприятий, производственные планы, графики отпусков, ремонтов и пр.
Из приведенного примера понятно, насколько важны при хранении сведений об объектах связи между ними. Поэтому неудивительно, что первыми моделями данных (и, соответственно, базами данных) были следующие.
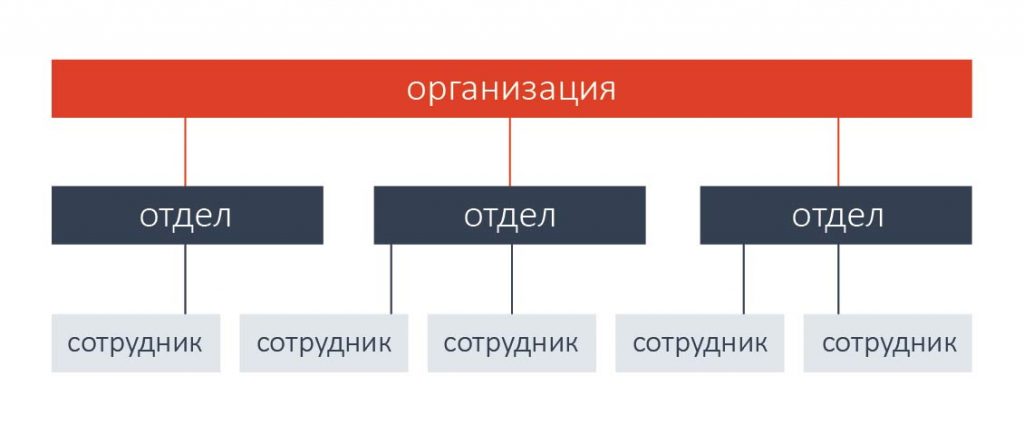
Иерархическая. Это наиболее естественная модель для отражения взаимосвязей в организациях и других иерархически организованных структурах.
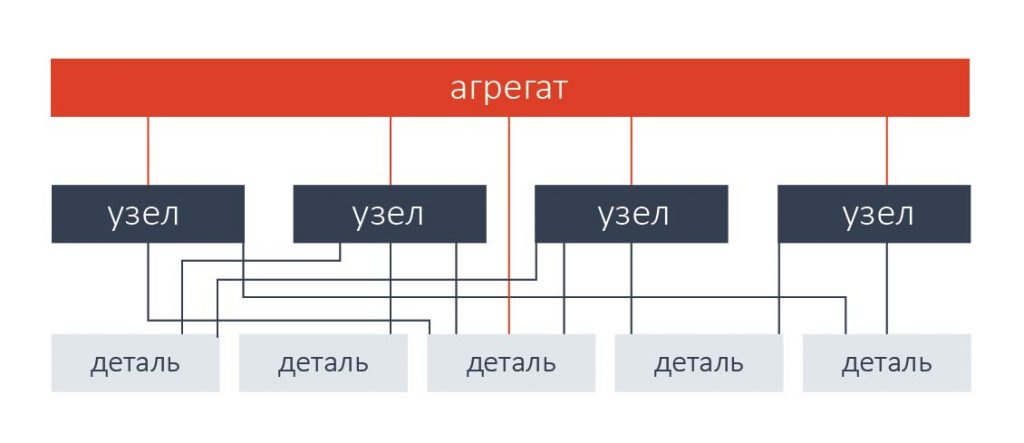
Сетевая. Для ряда задач иерархическая модель слишком жестка, необходимо ее расширение. Например, если одна и та же деталь входит в несколько узлов, в иерархической модели данных это отражено быть не может.
СУБД
Для управления базами данных используется специальные программные утилиты, получившие название систем управления базами данных (СУБД). Базы данных и СУБД часто путают, называя «базами данных» и то, и другое. Поэтому нелишне еще раз отметить:
База данных (БД) – это собственно данные в удобном для их хранения и обработки формате;
Система управления базами данных (СУБД) – это программа, которая умеет, с одной стороны, получать от пользователя или пользовательского приложения запросы на добавление, поиск и модификацию данных, с другой стороны, по запросам пользователя эти данные в базах искать, добавлять, извлекать, удалять, модифицировать.
Одна СУБД может управлять несколькими базами данных, и можно сказать, что у каждой СУБД свой формат баз данных.
Функциями СУБД являются также создание индексов, поддержка транзакций, обеспечение целостности данных, резервное копирование и восстановление, защита от сбоев и пр.
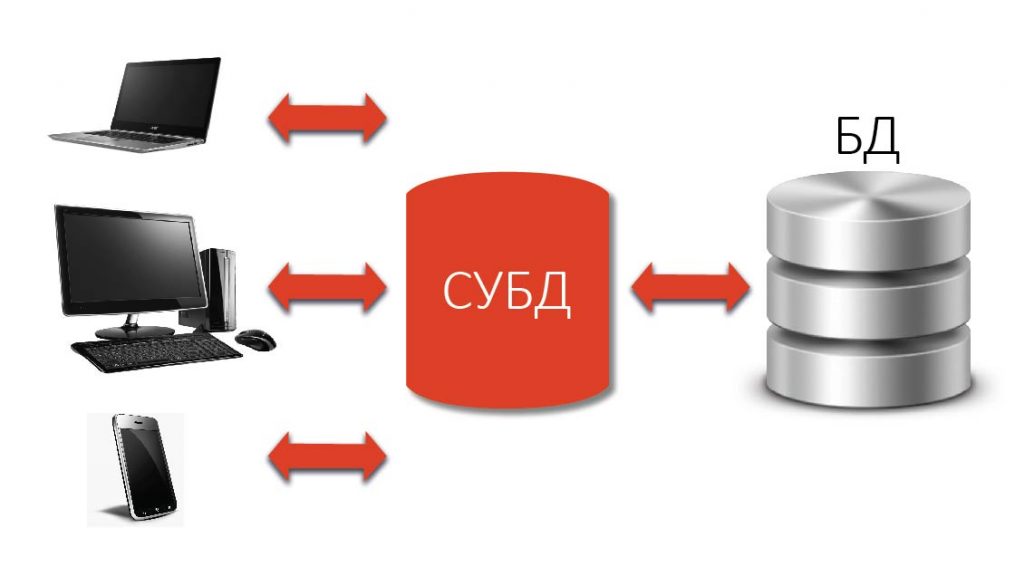
Как видно из рисунка, любая база данных управляется СУБД, доступна через СУБД, и только через СУБД. То есть, база данных и СУБД – это единый организм, одно без другого не существует.
Реляционная модель
В числе первых моделей данных, описанных выше, отсутствует самая, возможно, простая и базовая модель, возникшая даже раньше других, но долго не имевшая общепринятого названия. Иногда ее называли линейной, иногда табличной. Суть ее заключается в простом последовательном расположении сведений об объектах. Например, на рисунке ниже каждая строка представляет собой запись сведений об одном объекте, и эти записи расположены последовательно (линейно).
Такую модель можно рассматривать как вырожденную иерархическую или сетевую. Однако именно она впоследствии развилась в ставшую широко известной реляционную модель Кодда. В начале 70-х Эдгар Кодд [1] строго описал реляционную модель на основе разработанных им реляционной алгебры и реляционного исчисления.
Реляционная модель быстро завоевала популярность и стала использоваться повсеместно, отчасти в связи с тем, что в то время большая часть данных была слабо связанной и для большинства приложений было достаточно отдельных таблиц.
Однако иногда необходимо было связывать данные. В рамках реляционной модели это делалось довольно неудобным способом, и, что хуже, поиск по таким связям (операции соединения таблиц, JOIN), был очень медленным.
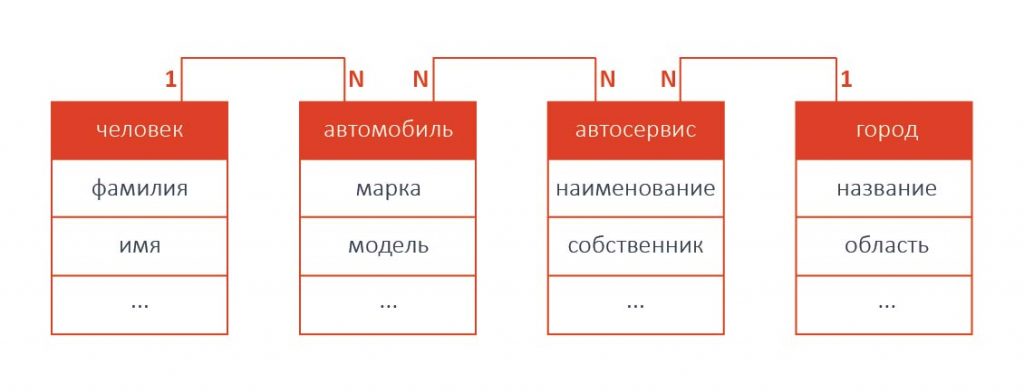
Производительность деградировала тем быстрее, чем больше соединяемых таблиц было задействовано в одном запросе. Например, если из базы данных, схема которой представлена на рисунке выше, требуется получить информацию о всех людях, имеющих автомобиль марки Toyota (одна операция JOIN), поиск будет достаточно быстрым. Однако если требуется получить информацию о всех людях, имеющих автомобили марки Toyota, ремонтировавшиеся в фирменных автосервисах, находящихся в определенном городе (четыре операции JOIN), скорость поиска будет намного ниже.
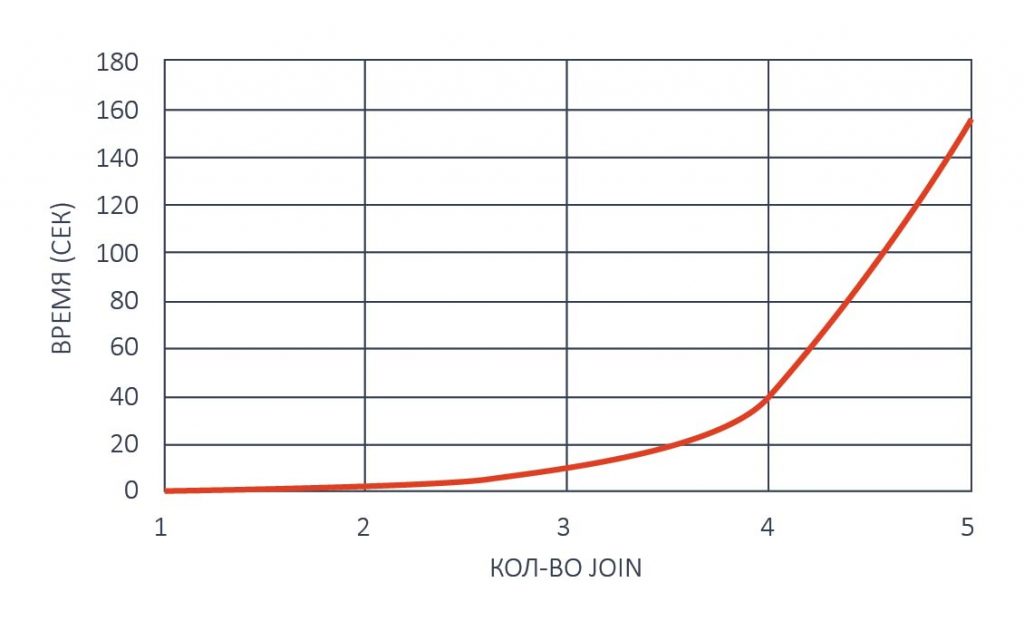
На рисунке выше видно, что рост времени поиска данных в реляционных базах данных в зависимости от количества операций JOIN может быть экспоненциальным.
Поскольку в эпоху становления реляционных баз данных «связей» было по сравнению с нынешним временем, немного, соответственно, выполнять запросы, требующие соединения таблиц, приходилось относительно нечасто, постольку неудобства работы с сильно связанными данными в рамках реляционной модели были проигнорированы.
Стандартизация реляционной модели, SQL
Большим достижением создателей реляционной модели явилась её стандартизация.
Были стандартизованы основные понятия и терминология, был разработан мощный язык запросов – Structured Query Language (SQL), на котором можно было выразить практически любое действие над базой данных. Поэтому реляционные СУБД часто называют SQL СУБД.
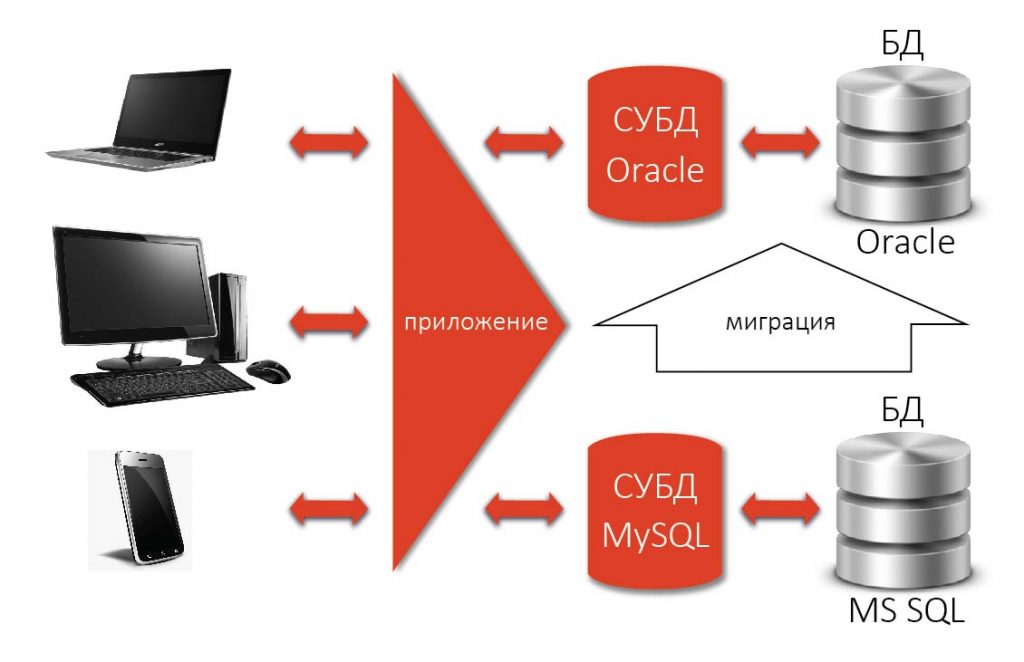
Стандартизация позволила в идеале безболезненно переходить (мигрировать) с одной реляционной СУБД на другую, не меняя разработанного приложения. На практике, конечно, такая миграция никогда не проходит гладко, но в целом это было большим шагом вперед по сравнению с практически полной несовместимостью существовавших тогда нереляционных СУБД.
По-видимому, именно эта стандартизованность явилась основным конкурентным преимущество реляционных СУБД. Для сравнения, объектным СУБД, развивавшимся в то же время, и обладавшим рядом архитектурных преимуществ, но так и оставшимся проприетарными в части, например, языков запросов, так и не удалось занять сколь-нибудь значительную долю рынка.
NoSQL, графовые базы данных
Реляционные базы данных доминируют и поныне, но к началу 2000-х появились тенденции, ставящие под сомнение дальнейшее их господство.
Развитие бизнеса в эпоху Internet привело не только к значительному увеличению объемов данных, но и существенному их усложнению. Можно сказать, что реляционные СУБД просто перестали справляться. Разочарование в реляционной модели привело к появлению альтернативных моделей, учитывающих новые реалии. Стали появляться и активно развиваться СУБД, основанные на модели ключ-значение, документные, колоночные и, наконец, графовые. Эти модели получили общее название NoSQL.
Среди всех NoSQL-моделей, по нашему мнению, наибольший интерес сегодня представляет графовая модель данных. Почему?
Во-первых, графовая модель сама по себе является наиболее естественным подходом к моделированию. Недаром сетевая модель данных, структурно близкая к графовой, являлась одной из первых моделей данных.
Во-вторых, наше время характеризуется ростом связности данных.
- Пожалуй, самый яркий тому пример — бум социальных сетей, на логическом уровне представляющих собой большие сильно связанные графы.
- Другой пример – постепенное превращение Интернета из большой «информационной свалки» в большую базу знаний. Чтобы превратить информацию в знания необходимо, хотя и недостаточно, так или иначе связать блоки информации между собой, и здесь отдельного упоминания заслуживает конкретная попытка этого превращения – проект «Semantic Web».
- Наконец, укрупнение и интеграция информационных сервисов, характерные для современного этапа развития корпоративных ИТ, сопровождаются объединением разнородных баз данных в единые комплексы, что весьма затратно реализуется на основе реляционной модели, но практически безболезненно может быть произведено с использованием графовой.
В-третьих, в начале XXI века Internet сообщество взяло курс на построение Semantic Web (Web 3.0) [2]. Напомним вкратце, что
- Web 0 – это Web разработчиков, эпоха, когда основной контент Web представляли простые сайты на основе статических HTML страниц, создаваемых разработчиками;
- Web 0 – это Web пользователей, эпоха развития социальных сетей, пользовательских интернет-сервисов, и т.п. – эпоха динамического контента, который на 90% создается пользователями;
- Web 0 – это «умный» Web, Semantic Web. большая часть контента будет создаваться и использоваться компьютерами. Пользователю и разработчику в Web 3.0 останется лишь самый верхний, сервисный слой.
Указанная тенденция выглядит достаточно долговременной. Так, в 2018 году аналитическое агентство Gartner в своем «Hype Cycle for Emerging Technologies» [3] указало на «Knowledge Graphs» как на восходящий тренд, и в 2019 году в «Technology Trends for 2019» «Graphs» по-прежнему сохраняют свое место.
Модели графовых СУБД. RDF, SPARQL
Существует две основных разновидности графовой модели данных: Property Graph и RDF-граф (RDF — Resource Description Framework).
Property Graph (пример его приведен на рисунке ниже) – это ориентированный граф, в котором вершины соответствуют «записям», а ребра — «связям» между ними. Дополнительно и ребра, и связи могут быть снабжены скалярными атрибутами.
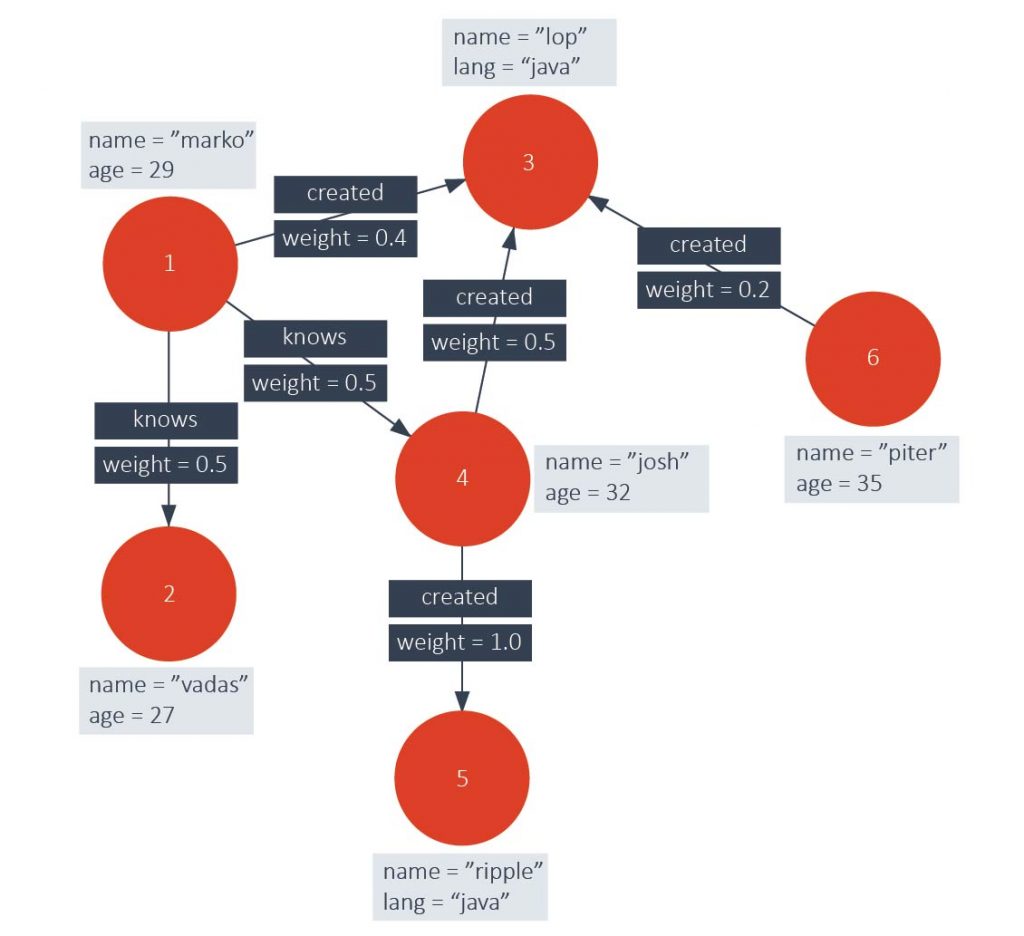
Наиболее известной СУБД, работающей с моделью Property Graph, является Neo4j. В основном, СУБД, работающие с Property Graph, имеют проприетарные интерфейсы и несовместимы друг с другом.
Модель данных RDF еще раньше развивалась в недрах науки искусственного интеллекта (ИИ) как один из способов представления знаний. После 2001 года, когда в журнале Scientific American была опубликована статья [2] знаменитого Тима Бернерса Ли (автора идеи всемирной паутины – World Wide Web), в Internet сообществе стал лавинообразно нарастать интерес к графовым базам, в частности, RDF. В 2004 г. RDF принят как стандарт комитета W3C (World Wide Web Consortium).
RDF – это формат задания графа, представленный в виде троек «субъект – предикат – объект».
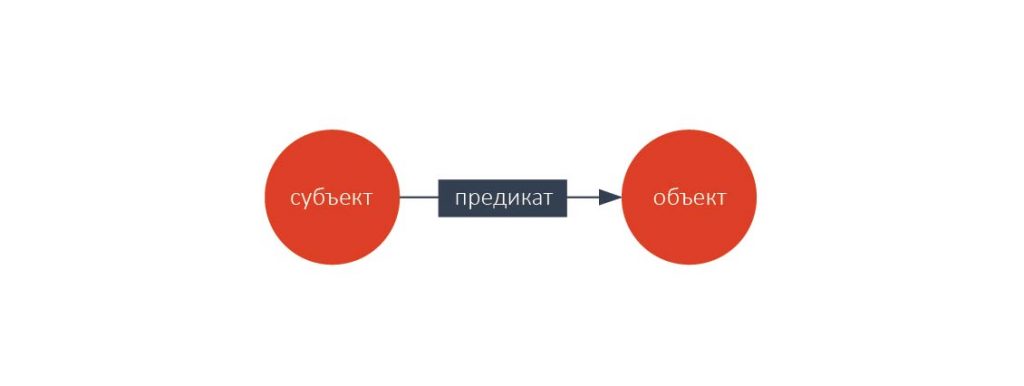
Пример на рисунке ниже показывает тройки, определяющие человека по имени Петр Иванов как автора некоторой статьи в журнале «Вопросы биологии».
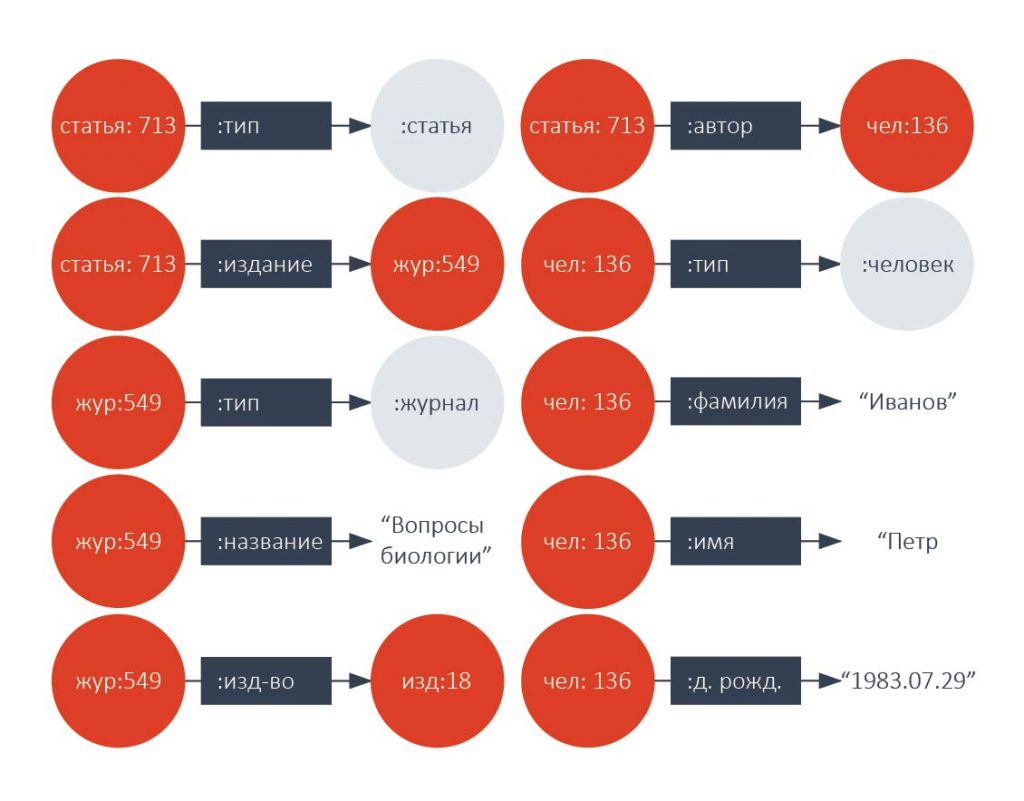
RDF тройки по несложным правилам логически могут быть «упакованы» в граф, изображенный на рисунке ниже.
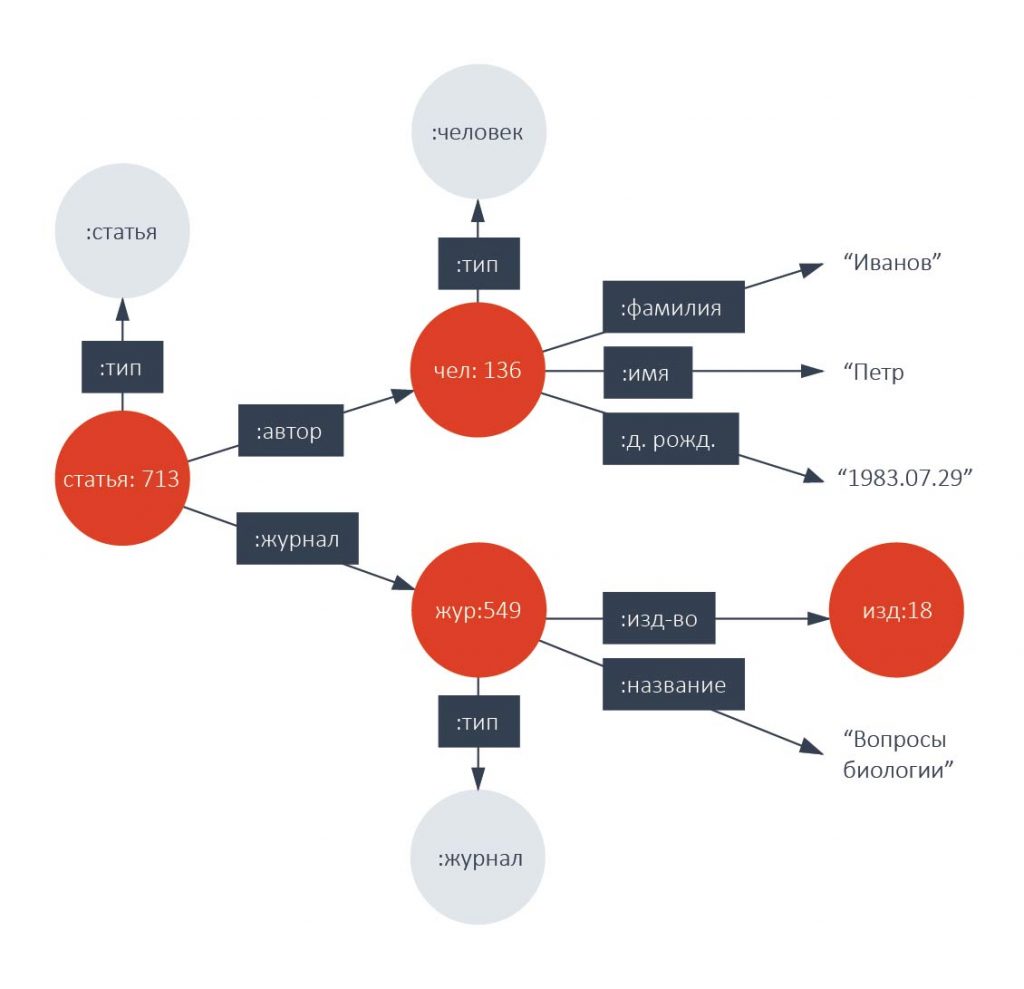
На графе, заданном таким образом, можно делать запросы с помощью специальных языков. Наиболее известный из них – язык, принятый в качестве стандарта W3C –SPARQL. Его синтаксис похож на SQL, язык SPARQL, как и SQL, имеет декларативную основу.
Например, на графе, фрагмент которого представлен на рисунке выше, можно с помощью SPARQL запроса найти всех авторов, печатавшихся в издательстве «Вопросы биологии», или, например, найти в каких издательствах печатался автор Петр Иванов, родившийся 29 июля 1983 г. и т.д., и т.п.
Что особенно важно, графовая RDF база данных гораздо легче проектируется, управляется и модифицируется, чем аналогичная реляционная база. Поиск сложных связей на этой модели также происходит с гораздо большей эффективностью, поскольку (при правильной архитектуре СУБД) все связи прямые, нет необходимости проводить операцию JOIN через внешние ключи.
Стандартизация RDF
Поскольку RDF вышел из ИИ, то он приспособлен для задач обработки знаний. Хотя, строго говоря, RDF – это информационная модель, она не достаточна для построения семантических систем. Зато модель RDF легкая и стройная, и пригодна для решения широкого круга задач, не только в рамках Semantic Web, но и в других прикладных областях. Для семантической обработки имеются стандартные расширения, совместимые с RDF, также принятые консорциумом W3C.
Благодаря усилиям консорциума W3C модель RDF удалось сделать гораздо более стандартизованной, чем это было достигнуто для реляционной модели.
- Язык SPARQL гораздо лучше стандартизован, чем SQL. Запросы на SPARQL можно смело посылать разным графовым RDF СУБД, содержащим одинаковые данные, результат будет одинаковым.
- RDF стандартизует также идентификацию информации (концепция URI – Universal Resource Identifier).
- Стандартизован протокол взаимодействия компонентов (HTTP), точка доступа SPARQL, и т.д.
Переход от SQL баз данных к RDF системам обещает такой же технологический скачок, как переход от самых первых СУБД к SQL.
Применения графовых СУБД
Можно выделить несколько направлений, в которых применение графовых СУБД наиболее эффективно.
Государственный сектор
Управление процессами, документооборот, аналитика, социологические исследования, и т.д. Клиентами могут быть федеральные и региональные министерства, исследовательские организации, и т.д.
Жизненный цикл предприятий
Интеграция и управление жизненным циклом предприятий в системах автоматизации предприятий. Применение графовых технологий дает возможность единообразно хранить и обрабатывать очень разнородную информацию, включая данные систем ERP, EAM, PLM, САПР и т.д. Клиенты – компании, переходящие на ISO 15926 и другие стандарты на основе RDF, например, Bentley, Siemens, OAK, OCK, Росатом, Роснефть, РАО ЕЭС и т.д.
Маркетинг, реклама, PR
Сбор и анализ разнородной информации из блогов, соц. сетей и т.д. для выявления источников информации, предпочтений пользователей; программы лояльности; SEO и т. д.
СМИ
Единая база событий, фактов, компаний, предприятий, журналистов, изданий, статей, сообщений и т.д.
Оборона
АСУ вооруженными силами; системы распределения военной информации; системы планирования войсковых операций; системы анализа и поддержки принятия решений на ТВД; средства автоматизации процессов боевого информационного обеспечения и управления войсками; тренажерные системы; и т.д.
Безопасность
Анализ логов, электронной почты, интернет трафика; финансовый анализ; анализ информации о людях из разных источников, включая данные о работе, собственности, доходах; анализ информации о связях и интересах из социальных сетей; поиск связей по аффилированности и т.д. Возможные клиенты – службы безопасности банков и предприятий, холдингов, корпораций и т.д.
Бизнес-аналитика
Построение аналитических систем нового поколения; построение систем Semantic Data Warehouse – нового класса хранилищ, использующего взаимосвязи данных для повышения качества принятия решений. Клиенты – государственный сектор, банки, предприятия, корпорации, страховые компании и т.д.
Управление сетями и дата-центрами
Управление жизненным циклом вычислительных комплексов, дата-центров, компьютерных и телекоммуникационных сетей и т.д.; моделирование и оптимизация взаимодействия физического, сетевого и других. уровней. Возможные клиенты – дата-центры, Internet провайдеры, службы коммуникаций и кибербезопасности.
Социальные приложения, рекомендационные сервисы и коммерция
Построение и анализ социальных графов. Применение графовых подходов позволяет выявлять модели аналогичного поведения, групп влияния, неявных групп, и т.д. Возможные клиенты: Компании-разработчики Web-сервисов для более тонкого учета предпочтений клиентов; разработчики приложений для мобильных устройств, Интернет-торговли, форумов и социальных сетей.
Образование
Построение графа взаимосвязей между терминами, понятиями, программами обучения, задачами, тестами, знаниями учащегося и т.д. для построения адаптивных обучающих систем. Клиенты – учебные заведения, провайдеры систем дистанционного обучения.
Геосервисы, геоприложения
Построение взаимосвязей разнородных данных на карте, связанной с людьми, местами и событиями, компаниями, предприятиями и т.д.; решение задач логистики, маршрутизации и т.д. Возможные клиенты –Министерство обороны, МЧС, другие министерства, разработчики социальных приложений и т.д.
Проблемы графовых СУБД
Графовые СУБД в силу своей гибкости и универсальности завоевывает все большее место на рынке. Но широкому их распространению по-прежнему мешает проблема их сравнительно низкой производительности на простых запросах, а именно:
- С одной стороны, графовые базы деградируют гораздо медленнее, чем реляционные при увеличении кол-ва – связей.
- С другой стороны, они (имеющиеся на рынке реализации) изначально более медленные.
Таким образом, получается, что графовые СУБД проявляют свои преимущества только при большом количестве связей. Но для типовых современных приложений характерно кол-во связей (операций JOIN в терминах SQL баз) от 2 до 5. То есть, применение графовых СУБД в настоящее время ограничено только сильно связанными данными.
Решение – Графовая СУБД NitrosBase
Графовая СУБД NitrosBase RDF Storage целиком основана на технологии NitrosBase, которая создавалась и оттачивалась более 20 лет. Технологические новации NitrosBase занимают лидирующие позиции по производительности, что неоднократно было отмечено наградами на отраслевых выставках и конференциях.
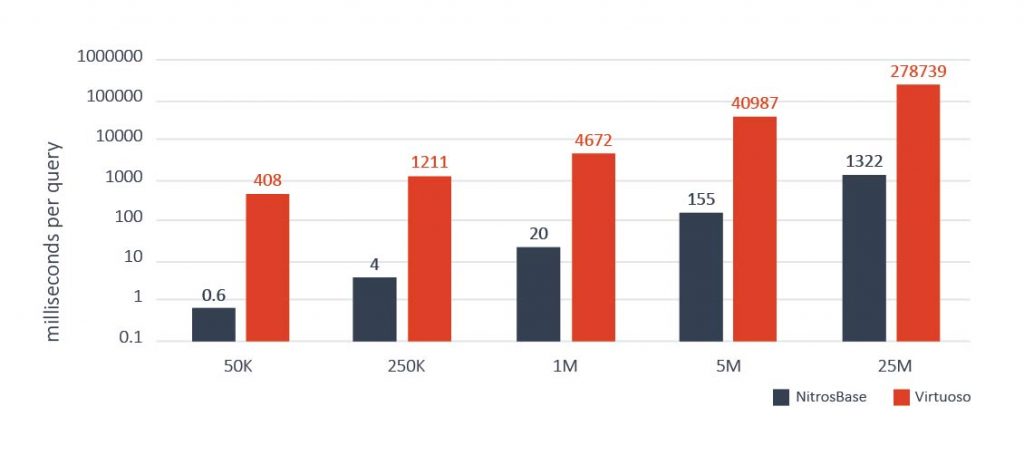
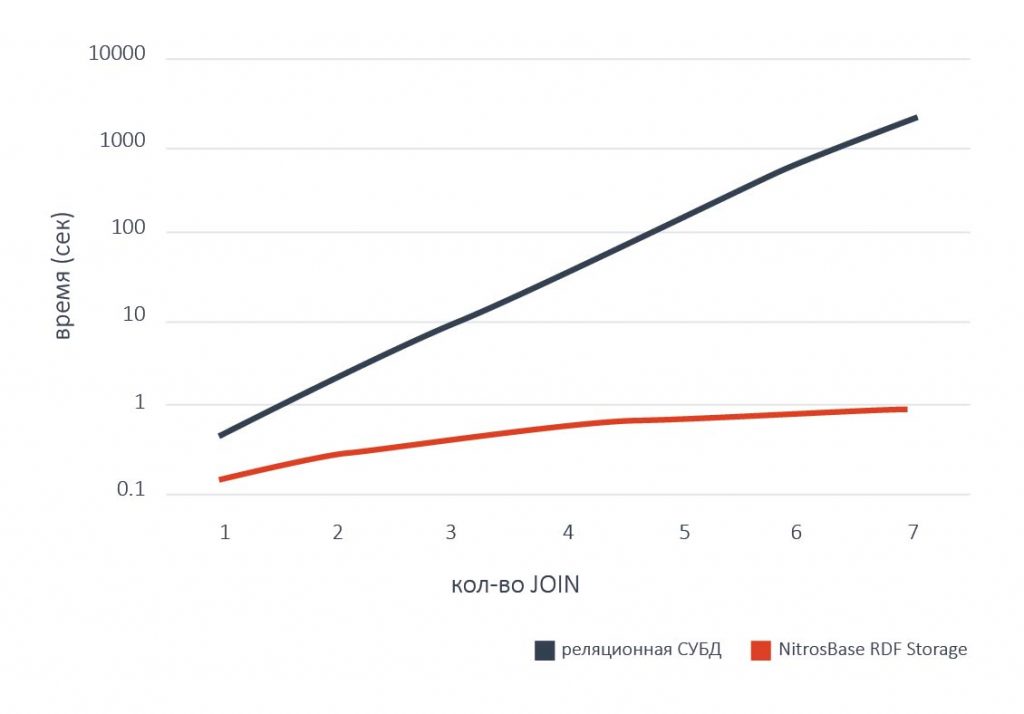
Проведенные нами сравнительные тесты широко известного набора SP2Bench показали значительное превосходство в производительности NitrosBase Storage над конкурентами. Например, на рисунке ниже показаны сравнительные результаты запроса 6 из набора SP2Bench. Запрос состоял в том, чтобы получить множество публикаций, авторы которых не публиковались ранее. Результаты показывают превосходство NitrosBase по сравнению с одной из наиболее производительных RDF СУБД более чем в 200 раз.
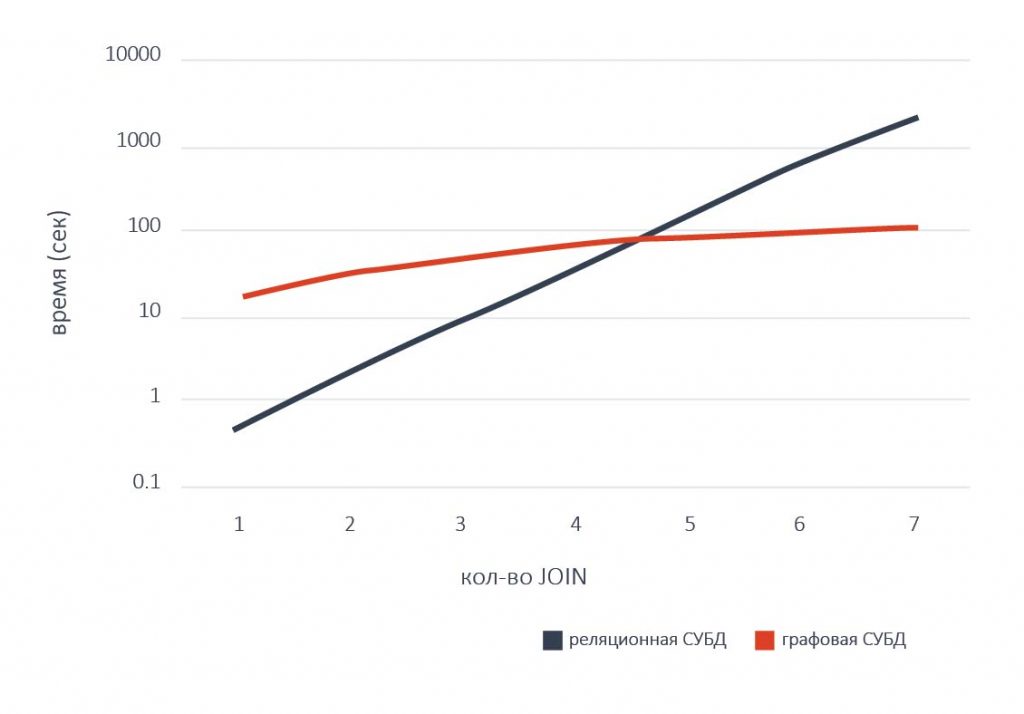
NitrosBase RDF Storage проявляет свои преимущества не только при большом количестве связей, она быстрее всех известных на рынке реляционных СУБД даже при небольшом количестве связей, характерном для типовых современных приложений.
С помощью NitrosBase можно уже сейчас начать широкое распространение графовых СУБД для всех имеющихся на рынке ниш обработки данных.
Литература
- Codd, E.F. “A Relational Model of Data for Large Shared Data Banks”. Communications of the ACM 13 (6): 377–387. doi:10.1145/362384.362685 (June 1970).
- The Semantic Web. A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities – Tim Berners-Lee, James Hendler and Ora Lassila. Scientific American, May 17, 2001.
- Gartner Identifies Five Emerging Technology Trends That Will Blur the Lines Between Human and Machine. URL: https://www.gartner.com/en/newsroom/press-releases/2018-08-20-gartner-identifies-five-emerging-technology-trends-that-will-blur-the-lines-between-human-and-machine
- Gartner Identifies Top 10 Data and Analytics Technology Trends for 2019. URL: https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo